Recentemente, em um grupo de WhatsApp dedicado a entusiastas de redes, surgiu uma discussão sobre o Traceroute (e suas variantes, MTR/WinMTR). Percebi que muitos estavam com conceitos errôneos sobre essas ferramentas, possivelmente devido a falta de conhecimento aprofundado ou a uma compreensão incorreta do seu funcionamento. Frases como “se há perda de pacotes no caminho, também haverá no destino” e “sempre achei que a perda no caminho era prejudicial” foram comuns na conversa.
Diante disso, decidi escrever este artigo para esclarecer esses conceitos e tirar dúvidas sobre o assunto. Embora eu não seja um especialista, meu objetivo é estudar e realizar alguns testes e capturas de pacotes para entendermos melhor como essas ferramentas funcionam e como interpretar corretamente os resultados que elas fornecem.
Vamos lá.
Primeiramente vamos alinhar algumas noções fundamentais para termos o entendimento de como essas ferramentas funcionam por baixo dos panos.
TTL e Hop Limit:
O TTL (Time To Live) é um campo no cabeçalho do pacote IPv4 que originalmente foi feito para limitar o tempo em segundos que um pacote pode ficar na rede. Porém posteriormente foi modificado para os valores que vão de 1 a 255.
A cada roteador pelo qual o pacote passa, o TTL é reduzido em 1. Quando o TTL chega a 0, o pacote é descartado. Isso evita que pacotes fiquem circulando indefinidamente na rede devido a loops.
O Hop Limit desempenha uma função semelhante ao TTL no IPv4. É o campo no cabeçalho do pacote IPv6 que limita o número de saltos (hops) que um pacote pode fazer através dos roteadores. O nome foi alterado para Hop Limit, pois desde o IPv4, não fazia mais sentido o conceito de “Time” To Live do pacote, já que o mesmo não era mais medido em segundos. Assim como o TTL a cada salto, o valor do Hop Limit é decrementado.
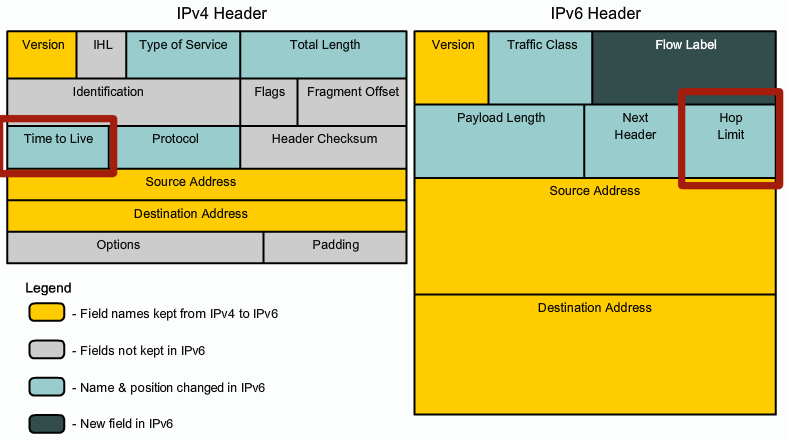
Quando o TTL (no IPv4) ou o Hop Limit (no IPv6) de um pacote chega a zero, o pacote é descartado pelo roteador que detecta o valor zero. Nesse caso, o roteador geralmente* envia uma mensagem de erro de volta para o remetente original do pacote. Para IPv4, isso é feito com uma mensagem ICMP (Internet Control Message Protocol) de tipo “Time Exceeded”. No IPv6, o protocolo correspondente é o ICMPv6, que também envia uma mensagem de “Time Exceeded” para informar que o pacote foi descartado devido ao Hop Limit ter chegado a zero.
Por que “geralmente”? Vamos entender mais para frente que em muitas vezes, diversos fatores farão com que essas mensagens nunca aconteçam.
RTT: Significa “Round-Trip Time” (Tempo de Ida e Volta). Utilizado na ferramenta para sabermos quanto tempo leva para os pacotes chegarem e retornarem de cada salto. É medido em milissegundos (ms).
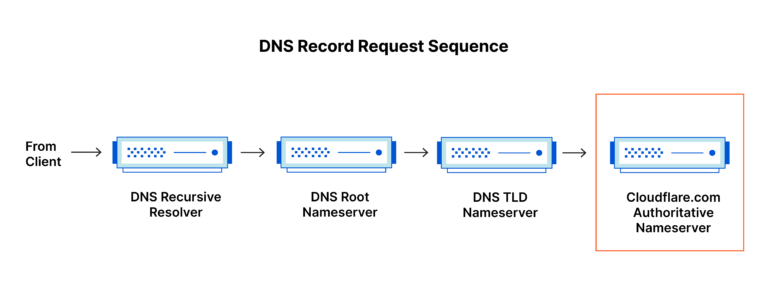
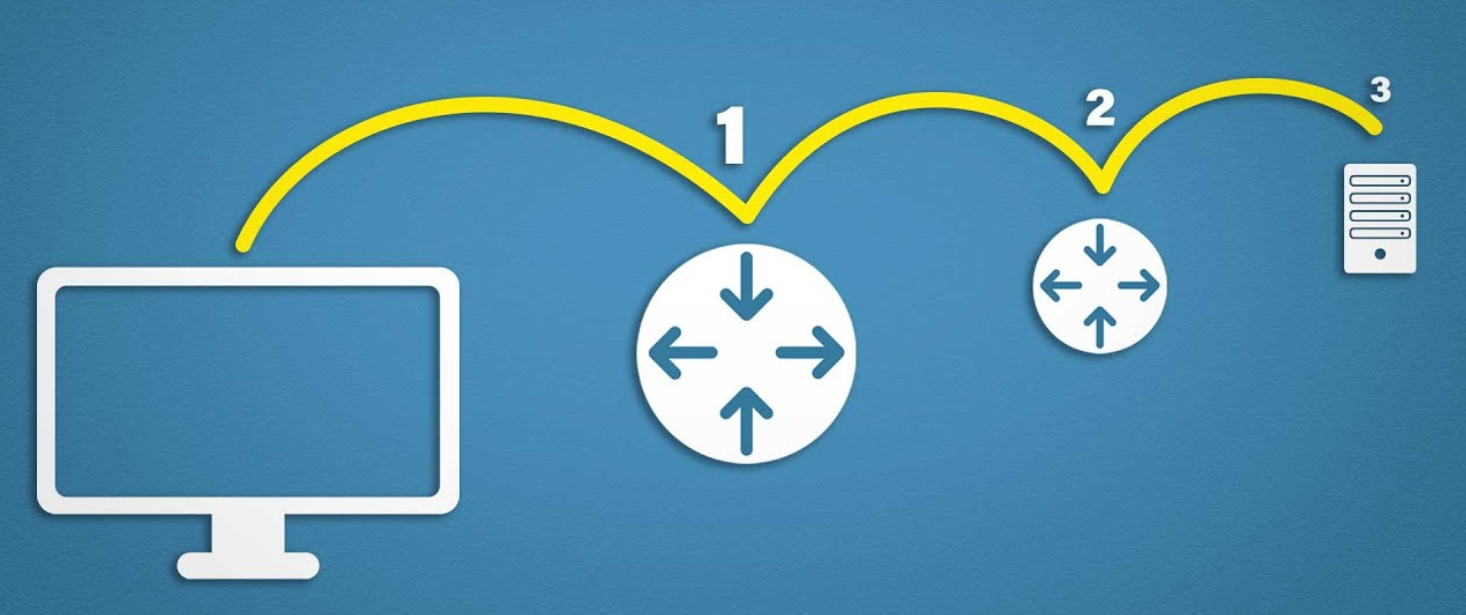
Então, agora fica facil entender como o traceroute funciona!
Basicamente a ferramenta envia pacotes com o TTL/Hop Limit limitado, que aumenta gradualmente a cada nova tentativa até chegar ao destino, para fazer com que os roteadores no caminho respondam a origem e consequentemente obtendo o endereço IP desses roteadores e é registrado o tempo de resposta. O GIF abaixo ilustra exatamente esse processo.

Algumas observações: Podemos chegar a conclusão que o traceroute obtem informação do caminho no sentido de Upload. E como o roteador tem que responder a origem quando o TTL/Hop Limit chega a 0, para evitar essa resposta, teria que ser feito filtros na chain: Output.
Vamos realizar testes práticos:
Topologia:

Temos dois end-points (um Linux Cliente e um Servidor Linux) e 5 roteadores Mikrotik no caminho.
Vamos realizar um simples teste de traceroute no sentido Cliente > Servidor
Por padrão, o traceroute envia três pacotes UDP para cada salto. Então irei utilizar o argumento -q 1 para reduzir em 1 pacote

Capturando os pacotes:

Podemos validar a jogada de TTL. O cliente enviou o pacote UDP com o TTL em 1, zerou ao chegar no roteador e o mesmo respondeu (com ICMP informando que o TTL expirou). (note que o TTL dele é 64, sendo o normal para a maioria dos roteadores ou linux).
OBS: No pacote do roteador para o cliente, o 1 após o 64 é referente ao TTL do pacote do cliente enviado anteriormente.

Pacotes dos outros saltos:
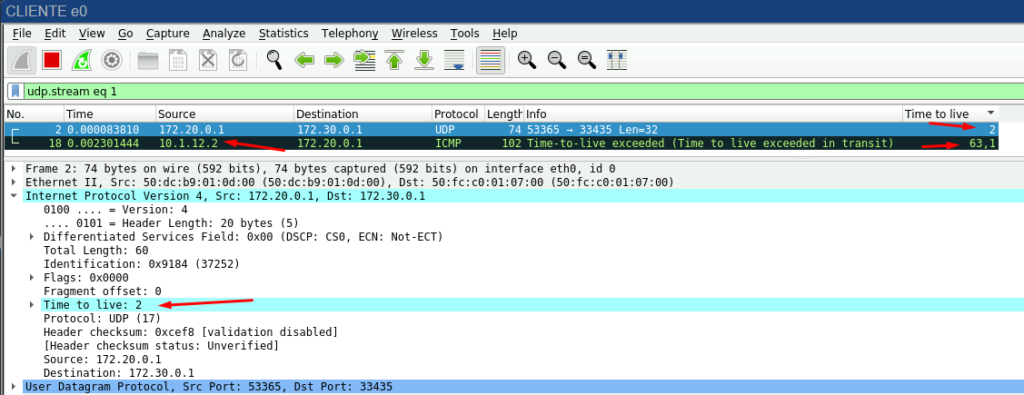

Podemos notar que cada pacote enviado pelo cliente, vai incrementando de 1 em 1 o TTL (e a resposta do roteador decrementando devido os roteadores anteriores) e em source, vemos que é o IP do roteador que respondeu ao traceroute e não o servidor.
Quando finalmente o cliente envia o pacote para o ip final, o destino, por não ter aquela porta UDP aberta, envia um ICMP com o codigo de port unreachable.
Exemplo:

Agora vamos testar algumas situações que podem ser vistas no traceroute em alguns troubleshoots da vida.
Irei usar o MTR por ser uma combinação do Ping e Traceroute. Por padrão utiliza ICMP nos pacotes

- Em Hosts podemos ver todos os saltos, sendo o ultimo o proprio destino
- Loss% informa a porcentagem de perdas de pacotes
- Snt a quantidades de probes (sondas) enviadas
- Last/Avg/Best/Wrst = Ultimo/Média/Melhor/Pior valor de latência (RTT)
- StDev ou Desvio Padrao é conhecido como Jitter (a variação do Best e Wrst)
Situação 1: Loss no meio do caminho
Essa situação gera dúvidas, porém como vimos anteriormente quem responde ao cliente sempre é o roteador no caminho e essas perdas podem ocorrer por alguns motivos:
- Rate-limit de ICMP no roteador;
- Roteador priorizando Forward dos pacotes e não Input/Output. Ou seja, ele encaminha normalmente os pacotes mas pode ter dificuldade de estar respondendo que o TTL zerou para a origem.
Conforme Video, podemos notar que não afeta a conectividade Cliente x Servidor
Situação 2: Sem resposta no meio do caminho
Básicamente acontece por:
- Bloqueio do ICMP nos roteadores;
- Backbone MPLS, por conta que os roteadores no caminho apenas irão ler labels e não irão analisar o cabeçalho IP e verem que o TTL zerou;
- Backbone MPLS ocultado por motivos de segurança;
- Roteadores que não possuem as rotas externas para esse IP de origem.
Não afeta a conectividade Cliente x Servidor
Situação 3: Perdas de pacote a partir de um determinado salto até o destino
Essa é uma situação que impacta na comunicação Cliente x Servidor.
Podemos notar que A PARTIR do salto 3 (10.1.23.2) em diante começou a ter perdas de pacotes e todos os outros após ele foram afetados. Vemos também que os testes de pings no Servidor > Cliente apresentou alta latência e perdas de pacotes (note buracos nos icmp_seq).
Esse é um cenário para se preocupar e que requer maior análise. O motivo pode ser diversos fatores.
Situação 4: Perdas apenas no cliente
Obviamente impacta na comunicação Cliente x Servidor. O motivo pode ser diversos fatores.
BONÛS:
Redirect
Recentemente estive fazendo um lab (que posteriormente irei documentar aqui no blog) e me deparei com uma situação de Redirect pelo gateway, o que afetou na saida do traceroute. Devido a isso irei exemplificar e explicar o que ocorreu.
Topologia:

A maquina cliente tem como gateway o IP 100.100.1.1, que por sua vez tem como gateway o 100.100.1.251 (ou seja, as 3 maquinas estão na mesma rede) e o destino tem como gateway para a rota default o seu ponto a ponto com outro roteador do backbone OSPF.
Captura de pacote:
Ao realizar o tracert na maquina cliente para o roteador que esta em outra rede, primeiro o PC enviou o ARP para ter o MAC do seu gateway (1) e encaminhou os pacotes ICMP e não houve a resposta (2). Então o gateway respondeu com ICMP Redirect informando para utilizar outro IP de gateway, no caso o 100.100.1.251 (3). Após isso a maquina fez a requisição de ARP, obteve o MAC do 100.100.1.251 (4) e começou a encaminhar os pacotes para ele normalmente (5).

Podemos ver que no cliente o hop 1 fica sem informações. Por isso afetou a saida do traceroute e quis trazer aqui para complementar.

Conclusão
Compreender o TTL (Time-To-Live), Hop Limit e o RTT (Round-Trip Time) é essencial para entendermos como o comando traceroute opera e para interpretarmos de forma correta as informações que essa ferramenta nos proporciona.